About NetPulse AI
NetPulse AI is a multi-agent telecom operations assistant built for the APAC GenAI Academy 2026 hackathon. A natural-language complaint goes in; a structured incident ticket comes out — complete with the related network events the operator should know about, the CDR findings that back up the customer’s account of what happened, and a recommended NOC action plan.
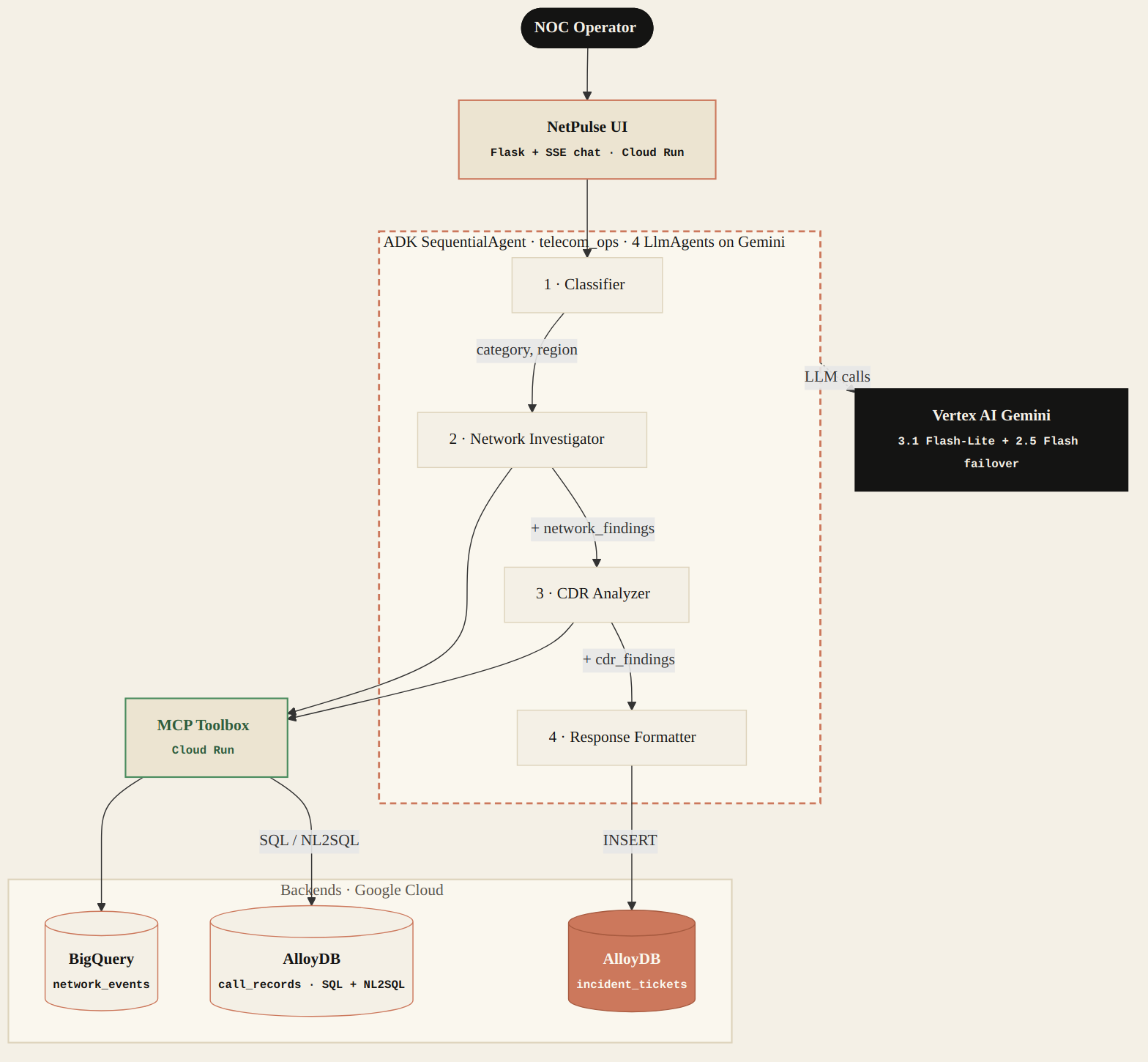
Architecture in detail
The core ADK package telecom_ops exposes a
SequentialAgent that runs four LlmAgent sub-agents
in order: classifier, network investigator, CDR analyzer, response
formatter. Each one reads the shared session state, queries its data
store through the MCP toolbox, and enriches the state for the next.
The fourth writes a structured ticket to the bundled SQLite store and the run ends.
Why a SequentialAgent
The four steps have strict data dependencies — the network
investigator can’t run until the classifier has tagged a region; the CDR
analyzer joins on the time window the network investigator returned;
the formatter needs all three to write a coherent ticket. A
SequentialAgent models this as code rather than encoding it
into a prompt, so the dependency stays correct under prompt churn.
Why MCP Toolbox in front of the data store
The toolbox-as-intermediary pattern gives one place to evolve tool
definitions without redeploying the agent service. Swap the toolbox
sources: block from kind: sqlite to a managed
backend (AlloyDB, Cloud SQL, BigQuery) and the agent code does not
change at all — only the toolbox YAML moves.
Why SQLite bundled in the container
The data substrate is a single ~10 MB SQLite file baked into the
container image. Two reasons that mattered for this iteration: zero idle
cost (no AlloyDB cluster or BigQuery dataset to keep alive), and a
demo that boots clean on a fresh project with no infra setup —
scripts/build_sqlite.py regenerates the file from the seed
CSVs in seconds. Trade-offs: no cross-instance ticket durability on Cloud
Run scale-to-zero, and no NL2SQL story (AlloyDB AI’s
execute_nl_query is AlloyDB-specific). The two
parameterized CDR tools cover the demo’s prompt surface; durable
ticket persistence is a managed-backend upgrade away.
Tech stack on Google Cloud
The complete list of moving parts. Everything is Google Cloud (the hackathon track requires it); the LLM-side work is Vertex AI Gemini.
output_key handoffs.gemini-3.1-flash-lite-preview at the global endpoint, with a 4-attempt model ladder failing over via gemini-3-flash-preview to gemini-2.5-flash under quota pressure.network_events table inside the bundled SQLite file — 50,000 events across 10 metros over a 6-month rolling window. Indexed on (region, severity, started_at) for the time-windowed scans the network investigator runs.call_records served by two parameterized SQL tools: query_cdr_summary (call_type × call_status breakdown) and query_cdr_worst_towers (per-tower failure ranking). Both execute in <50ms.incident_tickets — append-only writes via the native ADK tool save_incident_ticket. AUTOINCREMENT picks up from the seed’s MAX(ticket_id)+1 so agent-written tickets don’t collide with seeds.telecom_network_toolset, 2 in cdr_toolset) served by the genai-toolbox v0.23.0 binary against the same bundled SQLite file. Agents reach the data via the toolbox; the toolbox reaches the file via kind: sqlite-sql.netpulse-ui wraps the same root_agent in a hero landing + workspace timeline. Each request runs its own asyncio loop in a worker thread; events stream out incrementally via Server-Sent Events.netpulse-ui serves the chat surface; network-toolbox hosts the MCP toolbox. Both built from a Dockerfile in the project root, deployed from main.Data schema three surfaces
Three data surfaces feed the run. Each viewer page describes its schema and filter dimensions in detail.
Bring your own data in three steps
NetPulse AI ships with seed data for ten Indonesian metros. Adapting to a different telecom dataset is a three-step exercise:
- Replace the seed CSVs in
docs/seed-data/with your ownnetwork_events.csv,call_records.csv, andincident_tickets.csv. Keep the column shapes intact — see network events schema and call records schema for column-by-column descriptions. - Re-run
python scripts/build_sqlite.py --recreateto wipe the existingdata/netpulse.sqliteand rebuild from your CSVs. The script materializes all three tables in one go and is idempotent. - Adjust the region whitelist in
netpulse-ui/data_queries.py(ALLOWED_REGIONS) and the prompt examples intelecom_ops/prompts.pyif your cities diverge from the Indonesian-metro defaults. The agents will pick up the new vocabulary on next deploy.
The agents themselves are dataset-agnostic — what changes is the
data, the region whitelist, and the parameterized-SQL bodies in
toolbox-service/tools.yaml if your schema diverges.
Phase history over time
NetPulse AI was built through a series of timeboxed phases. Each phase landed in a single PR (in most cases) and was visually verified end-to-end before the next began.
- May 17, 2026ArchitecturePhase 13 — SQLite reconstitution: BigQuery + AlloyDB collapsed onto a single bundled SQLite file via MCP Toolbox
kind: sqlite-sql→ - April 29, 2026EngineeringPhase 12 — Vertex model-ladder failover replaces region ladder→
- April 28, 2026ArchitecturePhase 11 — AlloyDB AI NL2SQL replaces hand-written CDR SQL (later removed in Phase 13)→
- April 27, 2026RefactorPhase 10 — MCP toolbox refactor 8 tools → 2 universal tools→
- April 26, 2026EngineeringPhase 9 — Flash-Lite collapse + observer pill model unification→
- April 25, 2026ShipPhase 8 — Single consolidated Cloud Run redeploy→
- April 24, 2026FoundationPhases 1–7 — Refinement runway: audit → tokens → region failover → visual redesign → UX fixes → reproducibility → story polish→
- April 23, 2026MilestoneTop 100 — APAC GenAI Academy 2026 selection→
Roadmap next
The hackathon scope is a refined prototype, not a product. These are the next directions if the project continues past 2026-04-30.